缓存行伪共享
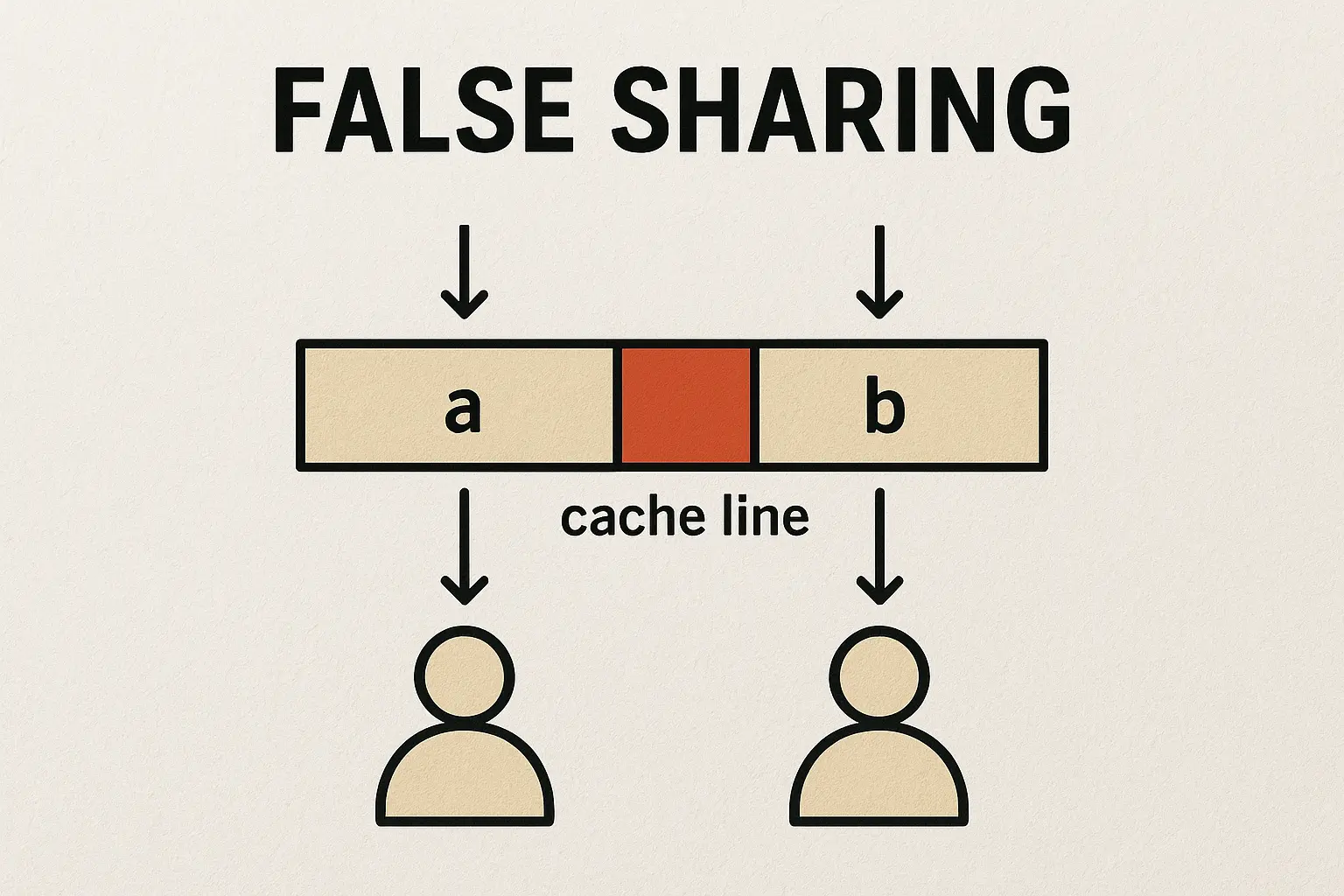
1. 背景:CPU 缓存与 Cache Line
- CPU 缓存是为了加速内存访问引入的高速存储。
- 缓存不是一字节一字节加载,而是以 缓存行(Cache Line) 为单位,常见大小是 64 字节。
- 当 CPU 访问某个变量时,整个缓存行(包含这个变量周围的数据)都会被加载到 CPU 缓存中。
2. 什么是伪共享?
伪共享是指:
- 两个或多个 逻辑上互不相关 的变量(例如队列的
head和tail指针),在 物理内存上相邻,从而落在同一个缓存行里。 -
如果不同线程分别操作这些变量,由于缓存一致性协议(MESI 等)的存在:
- 一个线程修改
a,会让整个缓存行失效; - 另一个线程即使只读/写
b,也必须重新从内存同步缓存行。
- 一个线程修改
- 结果就是 不必要的缓存行失效与同步开销,极大影响多线程程序的性能。
📌 关键词:共享缓存行,但逻辑上不该共享 —— 所以叫 “伪共享”。
3. 举个例子
假设缓存行大小为 64 字节:
class Example {
volatile long a; // 8 字节
volatile long b; // 8 字节
}
a和b在内存上是连续的(共占 16 字节)。- 如果它们被不同线程频繁修改,就会落在同一个缓存行。
- 即使线程 1 只改
a,线程 2 只改b,它们也会互相干扰(缓存行失效)。
4. 如何解决伪共享
常见方法是 填充(padding),让不同变量不落在同一缓存行:
(1) 手工填充字段
class Example {
volatile long a;
long p1, p2, p3, p4, p5, p6, p7; // 填充,防止 b 与 a 同一行
volatile long b;
}
(2) 使用注解 @sun.misc.Contended(JDK 8+)*
@sun.misc.Contended
class Example {
volatile long a;
volatile long b;
}
@Contended会在字段前后自动加上填充字节,保证它们分离在不同缓存行。- 需要 JVM 参数
-XX:-RestrictContended启用。
⚠️ 警告:此方法在高版本 JDK 中已过时(我测试使用的是 OpenJDK 24),不能再使用了,
即使使用 @jdk.internal.vm.annotation.Contended (JDK 9+)也不行,这也是内部 API,
官方不推荐在生产环境中直接使用。建议使用第一种手动填充或第三方库(JCTools)
5. 什么时候会遇到伪共享?
- 高并发队列的
head/tail指针(生产者消费者模型)。 - 计数器数组(例如统计请求数的场景)。
- 自旋锁、原子变量等高频修改的共享数据结构。
6. 总结
- 伪共享不是“共享数据”,而是“共享缓存行” 导致的问题。
- 本质原因:缓存一致性协议 + 内存排布紧密。
- 解决思路:避免热点变量处于同一个缓存行(padding 或
@Contended)。
通过以下带伪共享和去伪共享对比的 Java Benchmark 代码(JMH),让我们直观看看性能差距:
JMH 基准测试代码
创建一个 Maven 项目,并添加 JMH 依赖。
1. Maven 依赖 (pom.xml)
<project ...>
<properties>
<maven.compiler.source>24</maven.compiler.source>
<maven.compiler.target>24</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.37</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.37</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
2. Java Benchmark 代码
这个类包含了两种情况的测试:
StateWithFalseSharing: 两个volatile long变量紧挨着,极易产生伪共享。StateWithoutFalseSharing: 在两个volatile long变量之间填充了 15 个long作为“垫料”,避免了伪共享。
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.ThreadParams;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.Throughput) // 测试模式:吞吐量 (每秒操作数)
@OutputTimeUnit(TimeUnit.SECONDS) // 输出结果的时间单位:秒
@Warmup(iterations = 5, time = 1) // 预热:5轮,每轮1秒
@Measurement(iterations = 5, time = 1) // 测量:5轮,每轮1秒
@Fork(1) // Fork 出一个进程进行测试
@State(Scope.Group) // 状态的作用域,Group 作用域保证同一组的线程共享实例
public class FalseSharingBenchmark {
/**
* 存在伪共享问题的状态类
*
* value1 和 value2 很可能在同一个缓存行 (64 字节) 中
* 因为 long 是 8 字节,两个 long 是 16 字节,远小于 64 字节
* 添加 @State 注解,Scope.Group 表示同一组的线程共享此实例
*/
@State(Scope.Group)
public static class StateWithFalseSharing {
public volatile long value1 = 0;
public volatile long value2 = 0;
}
/**
* 通过缓存行填充解决了伪共享问题的状态类
*/
@State(Scope.Group)
public static class StateWithoutFalseSharing {
public volatile long value1 = 0;
// 填充 7 个 long 再加上前一个 long (7 * 8 + 1 * 8 = 64 字节),超过一个缓存行的大小(通常一个缓存行是 64 字节)
// 确保 value1 和 value2 落在不同的缓存行
private long p1, p2, p3, p4, p5, p6, p7;
public volatile long value2 = 0;
}
// --------------- 基准测试方法 ---------------
@Benchmark
@Group("FalseSharing") // 将两个线程的操作归为一组
@GroupThreads(2) // 使用两个线程
public void testFalseSharing(StateWithFalseSharing state, ThreadParams threadParams) {
// 根据线程索引,让两个线程分别修改不同的变量
if (threadParams.getThreadIndex() == 0) {
state.value1++;
} else {
state.value2++;
}
}
@Benchmark
@Group("NoFalseSharing") // 将两个线程的操作归为另一组
@GroupThreads(2) // 同样使用两个线程
public void testNoFalseSharing(StateWithoutFalseSharing state, ThreadParams threadParams) {
// 根据线程索引,让两个线程分别修改不同的变量
if (threadParams.getThreadIndex() == 0) {
state.value1++;
} else {
state.value2++;
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(FalseSharingBenchmark.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
如何运行
- 将上述代码保存到你的 Maven 项目的
src/main/java目录下。 - 使用 Maven 构建项目:
mvn clean package - 可以直接在 IDE 中运行
main方法,或者执行打包后的 jar 文件。
预期结果分析
当你运行这个基准测试后,你会得到类似下面的输出(具体数值取决于你的机器配置,以下是我在 M1 Pro Mac 下得到的输出, 非伪共享版比伪共享版性能高 4 倍以上):
Benchmark Mode Cnt Score Error Units
FalseSharingBenchmark.FalseSharing thrpt 5 75292908.335 ± 17920363.242 ops/s
FalseSharingBenchmark.NoFalseSharing thrpt 5 329029833.864 ± 1406771.525 ops/s
结果解读:
FalseSharing组: 吞吐量(Score)非常低。这是因为两个线程在不断地修改位于同一缓存行的value1和value2。线程 A 修改value1,导致线程 B 所在的 CPU 核心的缓存行失效;紧接着线程 B 修改value2,又导致线程 A 的缓存行失效。这种来回的“缓存同步”严重拖慢了执行速度。NoFalseSharing组: 吞吐量非常高,可能是前者的4 到 10 倍甚至更高。这是因为通过填充字节,value1和value2被强制分配到了不同的缓存行。线程 A 修改value1不会影响线程 B 缓存的value2,反之亦然。两个线程可以真正地并行执行,性能自然大幅提升。
这个 Benchmark 非常直观地量化了伪共享带来的性能惩罚,以及通过简单的内存布局优化(去伪共享)所能获得的巨大性能收益。